ZooKeeper简介
一、简介
1、简介
ZooKeeper是一个面向分布式应用程序的分布式开源协调服务,是用于维护配置信息、命名、提供分布式同步以及组服务的集中式服务,所有这些类型的服务都以某种形式被分布式应用程序使用。它被设计成易于编程,并且使用了一个数据模型,这个模型是按照文件系统中常见的目录树结构设计的。
- 设计目标
ZooKeeper是简单的(simple):ZooKeeper允许分布式进程通过共享的类似于标准文件系统组织方式的分层命名空间彼此协调;命名空间由数据寄存器组成–用ZooKeeper的说法称为znodes–它们类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
ZooKeeper是复制的(replicated):就像它所协调的分布式进程一样,ZooKeeper本身也通过一组名为ensemble的主机进行复制。
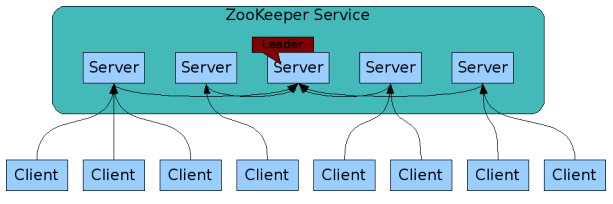
组成ZooKeeper服务的服务器必须互相了解,它们维护一个内存映像状态,以及持久存储的事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。
客户端连接到单个ZooKeeper服务器,通过维持一个TCP连接来发送请求、获取响应、获取观注事件(watch events)并发送心跳(heart beats)。如果它到服务器的TCP连接被中断,则将会连接到其他不同的服务器上。
ZooKeeper是有序的(ordered):ZooKeeper会在每个更新操作中加一个数字印记(stamp),反映所有ZooKeeper事务的顺序。后续的操作可以使用顺序来实现更高层次的抽象,比如同步原语。
ZooKeeper是快速的(fast):它在以读为主(read-dominant)的工作负载中特别快;ZooKeeper应用程序运行在成千上万台机器上,在读比写更常见的情况下性能最好,比例约为10:1。
- 数据模型和层次化命名空间
ZooKeeper提供的命名空间与标准文件系统的命名空间非常相似:名称是由一个斜线/分隔的路径元素序列,ZooKeeper命名空间中的每个节点都由一个路径标识。

- 节点
ZooKeeper命名空间中的每个节点都可以拥有与其关联的数据及子节点;ZooKeeper被设计用来存储协调数据: 状态信息、配置、位置信息等,因此存储在每个节点(znode)上的数据通常很小(b到kb)。
Znodes维护一个包含数据更改、ACL更改、时间戳版本号的属性结构,以支持缓存验证和协调更新。每当znode的数据发生变化时,版本号就会增加。例如,每当客户端检索数据时,它也会接收到数据的版本。当客户端执行更新或删除操作时,它必须提供所更改的znode的数据版本,如果它提供的版本与数据的实际版本不匹配,则更新将失败。
存储在命名空间中的每个znode中的数据可以自动读写。读操作可以读取与一个znode关联的所有数据,写操作可以替换数据内容。每个节点都有一个访问控制列表(ACL),用于限制谁可以做什么。
ZooKeeper也有临时(ephemeral)节点的概念:只要创建znode的会话(session)处于活动状态,那么这些znode就存在;当会话结束时,znode会被删除。
- 条件更新和监视(watche)
ZooKeeper支持监听的概念,客户端可以监听一个znode,当znode变化时watch将被触发并移除。当一个watch被触发时,客户端会收到一个说明znode已经改变的数据包。如果客户端和其中一个ZooKeeper服务器之间的连接中断,它将收到一个本地通知。
-
简单的API
ZooKeeper的设计目标之一是提供一个非常简单的编程接口;因此,它只支持以下操作:
-
create:在树中的某个位置创建一个节点
-
delete:删除节点
-
exists:判断某个位置的节点是否存在
-
get data:从一个节点读取数据
-
set data:将数据写入节点
-
get children:获取节点的子节点列表
-
sync:等待数据传播
-
2、安装
-
首先需要确保已安装1.8或以上的JDK。
-
下载Apache ZooKeeper并解压即可。
二、入门
本文以windows为例。
1、配置
在安装目录的conf目录下新建zoo.cfg文件,配置如下:
tickTime=2000
dataDir=F:/ProgramFiles/apache-zookeeper-3.6.2/data
clientPort=2181
其中:
-
tickTime是ZooKeeper使用的基本时间单位(毫秒),执行心跳的最小会话超时(session timeout)时间为两倍的tickTime。
-
dataDir是存储内存数据库快照的位置,以及数据库更新的事务日志。
-
clientPort表示侦听客户端连接的端口。
2、启动服务
切换到bin目录下,执行zkServer.cmd来启动ZooKeeper服务:
F:\ProgramFiles\apache-zookeeper-3.6.2\bin>zkServer.cmd
3、连接到ZooKeeper
启动客户端并连接到服务器:
zkCli -server 127.0.0.1:2181
连接成功后会看到类似以下的提示:
Welcome to ZooKeeper!
...
[zk: 127.0.0.1:2181(CONNECTED) 0]
使用help命令可以查看从客户端执行的命令列表;使用quit命令退出。
使用create、set、delete、get来增加、修改、删除和查看znode:

4、复制模式
上面的例子中ZooKeeper以独立(Standalone)模式运行,这种模式下运行方便开发和测试;但在生产环境中,应该以复制模式运行ZooKeeper。同一应用程序中的复制服务器组称为仲裁(quorum),在复制模式下,quorum中的所有服务器都具有相同配置文件的副本。
对于复制模式,至少需要三台服务器,并且强烈建议使用奇数个服务器。如果只有两个服务器,那么就会处于这样一种情况: 如果其中一个服务器出现故障,那么就没有足够的计算机来形成多数仲裁(quorum)。两台服务器的稳定性本质上不如一台服务器,因为存在两个单点故障。
复制模式所需的conf/zoo.cfg文件与独立模式中使用的类似,但有一些不同之处:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
其中:
-
initLimit用来限制quorum中的ZooKeeper服务器连接到leader的超时时间,上面的例子中为10秒(
2000*5)。 -
syncLimit用来设置服务器与leader同步的过期时间(可以落后于leader多久)。
-
server.x=ip:port1:port2列表表示组成ZooKeeper服务(service)的服务器。当服务器启动时,它通过在配置的数据目录(dataDir)中查找myid文件来知道它是哪个服务器,这个文件包含了以ASCII表示的服务器号。前一个端口用于对等点(peers)端到端的通信,更具体地说,ZooKeeper服务器使用这个端口将followers连接到leader;当一个新的leader出现时,followers使用这个端口打开一个到leader的TCP连接。另一个端口用来leader的选举。
由于我是在同一台机器上启动多个服务器,因此需要使用不同的端口,其中一个服务器的配置如下:
F:\ProgramFiles\apache-zookeeper-3.6.2\zookeeper-alpha\conf\zoo.cfg:
tickTime=2000
dataDir=F:/ProgramFiles/apache-zookeeper-3.6.2/zookeeper-alpha/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
F:\ProgramFiles\apache-zookeeper-3.6.2\zookeeper-alpha\data\myid:
1
其余两个配置类似,zoo.cfg中clientPort分别为2182、2183;对应的dataDir改为相应的目录位置;myid文件的值分别为2、3。
5、其他优化
为了获得更新的低延迟,拥有一个专用的事务日志目录非常重要。默认情况下,事务日志放在与数据快照和myid文件相同的目录下。
dataLogDir参数可以配置不同的事务日志目录。
三、编程指南
完整文档请参考:ZooKeeper Programmer’s Guide
1、Znodes
-
命名
ZooKeeper指向节点的路径是斜杠分隔的绝对路径,路径名为满足以下条件的Unicode字符:
-
空字符(\u0000)不能作为路径名的一部分
-
不允许使用
\ud800-uF8FF、\uFFF0-uFFFF、\u0001-\u001F和\u007F -
.可以用于表示另一个名称的一部分,但.和..不能单独使用,因为ZooKeeper不允许使用相对路径 -
不能使用
zookeeper这个保留字
-
-
类型
-
临时节点(Ephemeral Nodes)
只要创建znode的会话(session)处于活动状态,那么这些znode就存在;当会话结束时,znode会被删除。临时节点不允许有子节点;可以使用
getEphemerals()API获取会话(session)的临时节点列表。 -
顺序节点(Sequence Nodes)
在创建一个znode时,可以请求ZooKeeper在路径的末尾附加一个递增的计数器。此计数器对于父znode是唯一的。该计数器的格式为
%010d,即00000000001这种格式。用于存储下一个序列号的计数器是一个由父节点维护的带符号int(4字节)类型数字,当当计数器增量超过2147483647时将溢出(结果是
-2147483648)。 -
容器节点(Container Nodes)
容器节点是一些特殊用途的znodes,例如leader、lock等。一个容器的最后一个子元素被删除时,该容器将成为服务器在未来某个时刻要删除的候选容器。
-
TTL节点(TTL Nodes)
-
2、时间
ZooKeeper通过多种方式记录时间:
- Zxid
对ZooKeeper状态的每次更改都会收到一个Zxid(ZooKeeper事务Id)形式的戳记(stamp)。这将向ZooKeeper公开所有更改的总次序。每个更改都有一个惟一的zxid,如果zxid1小于zxid2,那么zxid1发生在zxid2之前。
- Version numbers
节点有三个版本号:znode数据的更改次数、znode子代的更改次数和znode ACL的更改次数;对一个节点的每次更改都会导致该节点的某个版本号增加。
- Ticks
使用多服务器ZooKeeper时,服务器使用计时器(ticks)来定义事件的计时,如状态上传、会话超时、对等点之间的连接超时等。
- Real time
ZooKeeper完全不使用实时时间(real time)或时钟时间(clock time),只是在znode创建和znode修改时将时间戳记放入stat结构中。
3、结构
ZooKeeper中每个znode的Stat结构由以下字段组成:
-
czxid:创建此znode的zxid
-
mzxid:上次修改此znode的zxid
-
pzxid:最后一次修改此znode的子节点的zxid
-
ctime:创建此znode的时间
-
mtime:最后一次修改此znode的时间(豪秒)
-
version:此znode数据的更改次数
-
cversion:此znode的子节点的更改次数
-
aversion:此znode ACL的更改次数
-
ephemeralOwner:如果此znode是一个临时节点,则是这个znode的所有者的session id;如果不是临时节点,则为零
-
dataLength:此znode的数据字段的长度
-
numChildren:此znode的子节点数
4、Watches
ZooKeeper的所有读操作:getData()、getChildren()和exists()都会对watch产生影响;ZooKeeper对watch的定义是:一个监视事件(watch event)是在监视的数据发生更改时一次触发并发送给客户端的事件。例如,如果客户端执行getData("/znode1",true),稍后更改或删除/znode1的数据,则客户机将获得/znode1的监视事件。如果/znode1再次被更改,将不会发送任何监视事件,除非客户端已经完成另一次读取并设置了新的监视。
可以通过调用读取ZooKeeper状态的三个方法来设置watch:exists、getData和getChildren。事件及事件的启用时机:
-
Created event:调用
exists时启用 -
Deleted event:调用
exists、getData和getChildren时启用 -
Changed event:调用
exists、getData时启用 -
Child event:调用
getChildren时启用
可以通过调用removeWatches来移除在znode上注册的watch;此外,ZooKeeper客户端可以通过将local标志设置为true 来删除本地手表,即使没有与服务器连接。成功删除watch后会触发的事件:
-
Child Remove event:通过调用
getChildren添加的watch被删除时触发 -
Data Remove event:通过调用
exists、getData添加的watch被删除时触发 -
Persistent Remove event:通过调用添加持久监视的方式添加的watch被删除时触发
5、ACL
ZooKeeper使用ACLs来控制对znodes(ZooKeeper的数据节点)的访问;ACL的实现与UNIX文件访问权限比较相似。
ACL只适用于特定的znode,尤其是它不适用于子节点,且ACLs不是递归的;例如:/app只能由ip:172.16.16.1可读,而/app/status是world可读的,那么/app/status是可以被任何人都能读取的。
-
ACL权限
ZooKeeper支持以下ACL权限:
-
CREATE:可以创建子节点
-
READ:可以从一个节点获取数据并列出它的子节点
-
WRITE:可以为节点设置数据
-
DELETE:可以删除子节点
-
ADMIN:可以设置权限
-
-
内置ACL方案
ZooKeeper有以下内置的方案:
- world
有一个单独的id:
anyone,代表任何人。- auth
Auth是一个特殊的方案,它忽略所提供的任何表达式,而是使用当前的用户、凭据和方案。
- digest
使用
username:password字符串生成MD5散列,然后将其用作ACL ID标识。- ip
使用客户端主机IP作为ACL ID标识。
- x509
X509使用客户机X500 Principal作为ACL ID标识。
6、一致性保证
ZooKeeper是一种高性能、可伸缩的服务,读操作和写操作都被设计成快速的。读操作比写操作快,是因为在读取的情况下,ZooKeeper可以提供旧的数据,而这又是由于ZooKeeper的一致性保证:
- Sequential Consistency
顺序一致性:客户端的更新将按照发送的顺序应用。
- Atomicity
原子性:要么更新成功,要么更新失败,没有部分结果。
- Single System Image
单系统映像:不管客户端连接到哪个服务器,看到的都是相同的视图。
- Reliability
可靠性:一旦应用了一个更新,它将从那个时候开始一直保持下去,直到客户机覆盖更新。
- Timeliness
及时性:客户的系统视图保证在一定时间范围内(大约数十秒)是最新的。
四、Java样例
1、安装
添加Maven依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.2</version>
</dependency>
2、API
- 连接
可以通过ZooKeeper类的构造方法连接到服务器:
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)
- create
创建一个znode:
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
参数分别为:znode路径、要存储的数据、访问控制列表、节点类型(临时节点、顺序节点等)。
- Exists
判断一个znode是否存在:
exists(String path, boolean watch)
exists(String path, Watcher watcher)
...
参数分别为:znode路径、是否监视指定的znode或指定的znode数据发生变化时的回调函数。
- getData
获取附加在指定znode中的数据及其状态:
getData(String path, boolean watch, Stat stat)
getData(String path, Watcher watcher, Stat stat)
...
参数分别为:znode路径、是否监视指定的znode或指定的znode数据发生变化时的回调函数、znode的元数据。
- setData
修改附加在指定znode中的数据:
setData(String path, byte[] data, int version)
参数分别为:znode路径、要存储的数据、znode的当前版本。
- getChildren
获取指定znode的所有子节点:
getChildren(String path, boolean watch)
getChildren(String path, Watcher watcher)
...
参数分别为:znode路径、是否监视指定的znode或指定的znode数据发生变化时的回调函数。
- delete
删除指定的znode:
delete(String path, int version)
参数分别为:znode路径、znode的当前版本。
3、样例
- 连接
ZooKeeperConnection.java:
public class ZooKeeperConnection {
private ZooKeeper zooKeeper;
private final CountDownLatch connLatch = new CountDownLatch(1);
public ZooKeeper connect(String host) throws IOException, InterruptedException {
zooKeeper = new ZooKeeper(host, 3000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(event.getState() == KeeperState.SyncConnected) {
connLatch.countDown();
}
}
});
connLatch.await();
return zooKeeper;
}
public void close() throws InterruptedException {
zooKeeper.close();
}
}
上面使用CountDownLatch让主进程等待直到客户端连接到ZooKeeper;一旦连接成功后,watcher回调中会调用CountDownLatch的countDown()方法来释放锁,在主进程中等待。
- Manager
public interface ZooKeeperManager {
void create(String path, byte[] data) throws KeeperException, InterruptedException;
Stat exists(String path) throws KeeperException, InterruptedException;
byte[] getData(String path) throws KeeperException, InterruptedException;
void update(String path, byte[] data) throws KeeperException, InterruptedException;
List<String> getChildren(String path) throws KeeperException, InterruptedException;
void delete(String path) throws InterruptedException, KeeperException;
void closeConnection();
}
- ManagerImpl
public class ZooKeeperManagerImpl implements ZooKeeperManager{
private ZooKeeper zooKeeper;
private ZooKeeperConnection connection;
public ZooKeeperManagerImpl() {
initialize();
}
private void initialize() {
connection = new ZooKeeperConnection();
try {
zooKeeper = connection.connect("localhost");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void create(String path, byte[] data) throws KeeperException, InterruptedException {
zooKeeper.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
@Override
public Stat exists(String path) throws KeeperException, InterruptedException {
return zooKeeper.exists(path, true);
}
@Override
public byte[] getData(String path) throws KeeperException, InterruptedException {
zooKeeper.getData(path, false, null);
return null;
}
@Override
public void update(String path, byte[] data) throws KeeperException, InterruptedException {
zooKeeper.setData(path, data, zooKeeper.exists(path, true).getVersion());
}
@Override
public List<String> getChildren(String path) throws KeeperException, InterruptedException{
return zooKeeper.getChildren(path, false);
}
@Override
public void delete(String path) throws InterruptedException, KeeperException {
zooKeeper.delete(path, zooKeeper.exists(path, true).getVersion());
}
@Override
public void closeConnection() {
try {
connection.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 测试类
public static void main(String[] args){
ZooKeeperManager manager = null;
try {
manager = new ZooKeeperManagerImpl();
String path = "/data";
String childPath = "/data/hello";
String helloWorld = "HelloWorld";
//create
manager.create(path, null);
manager.create(childPath, helloWorld.getBytes());
//exists
Stat stat = manager.exists(childPath);
if(stat != null) {
System.out.printf("Node exists and the node version is %s \n", stat.getVersion());
}else {
System.out.println("Node does not exists.");
return;
}
//getData
byte[] data = manager.getData(childPath);
System.out.printf("The data is %s \n", new String(data));
//getChildren
List<String> children = manager.getChildren(path);
System.out.printf("Children: %s \n", children);
//update
manager.update(childPath, "good night".getBytes());
//getData
data = manager.getData(childPath);
System.out.printf("The data is %s \n", new String(data));
//delete
manager.delete(childPath);
manager.delete(path);
//exists
stat = manager.exists(childPath);
if(stat != null) {
System.out.println("Delete failed, the node still exists.");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if(manager != null) {
manager.closeConnection();
}
}
}
- 运行结果
Node exists and the node version is 0
The data is HelloWorld
Children: [hello]
The data is good night
参考资料
ZooKeeper: Because Coordinating Distributed Systems is a Zoo