MySQL字符串处理
一、数据
以下数据仅为测试使用,无实际意义:
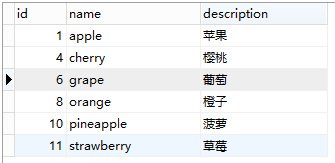
fruit表
| ID | 名称(name) | 描述(description) |
|---|---|---|
| 1 | apple | 苹果 |
| 2 | avocado | 南美梨 |
| 3 | banana | 香蕉 |
| 4 | cherry | 樱桃 |
| 5 | coconut | 椰子 |
| 6 | grape | 葡萄 |
| 7 | mango | 芒果 |
| 8 | orange | 橙子 |
| 9 | peach | 桃 |
| 10 | pineapple | 菠萝 |
| 11 | strawberry | 草莓 |
| 12 | watermelon | 西瓜 |
info表
此表中有三个字段:id、number和data,data为xml结构,值类似如下的xml:
<Student>
<Name>Jack</Name>
<Age>10</Age>
<Class>Class One Grade Three</Class>
<Address>2025 M Street, Northwest, Washington, DC, 20036</Address>
</Student>
二、正则表达式
MySQL中使用REGEXP操作符来进行正则表达式匹配:
- 匹配
name以a开头以do结尾的
select * from fruit where name REGEXP '^a[a-z]+do$';

- 匹配
name以che或str开头,以rry结尾的
select * from fruit where name REGEXP '^che|str[a-z]*rry$';
或
select * from fruit where name REGEXP '^(che|str)[a-z]*rry$';

- 匹配
name中以g或o开头的或者其中p或r出现2次以上的
select * from fruit where name REGEXP '(^[go].*)|(.*[pr]{2,}.*)';
- 匹配
name中an出现两次的
select * from fruit where name REGEXP '.*(an){2}.*';

三、字符串函数
1、大小写转换
LOWER(column|str)
select LOWER('HELLO');
select LOWER(name) from fruit where id = 1;

UPPER(column|str)
select UPPER('hello');
select UPPER(name) from fruit where id = 1;

2、字符串拼接
CONCAT(column1|str1, column2|str2, ...)
select CONCAT('hello', ' ', 'world');
select CONCAT(name, ' ', description) from fruit where id = 1;

CONCAT_WS(separator,str1,str2,...)
将多个字符串使用指定的连接符(separator)连接
select CONCAT_WS(' ','hello','world');
select CONCAT_WS(' ', name, description) from fruit where id = 1;

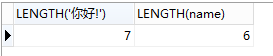
3、字符(串)长度
LENGTH(column|str)
返回字符串的存储长度
select LENGTH('你好!');
select LENGTH(description) from fruit where id = 1;
CHAR_LENGTH(column|str)
返回字符串的存储个数
select CHAR_LENGTH('你好!');
select CHAR_LENGTH(description) from fruit where id = 1;

4、字符串截取
LEFT(column|str,len)
select LEFT('hello world','5');
select LEFT(name,3) from fruit where id = 1;

RIGHT(column|str,len)
select RIGHT('hello world','5');
select RIGHT(name,3) from fruit where id = 1;

SUBSTRING(str,pos)
select SUBSTRING('hello world',2);
select SUBSTRING(name,2) from fruit where id = 1;

SUBSTRING(str,pos,len)
select SUBSTRING('hello world',2,3);
select SUBSTRING(name,2,3) from fruit where id = 1;

SUBSTRING_INDEX(str,delim,count)
#从开始位置截取到第一个o的位置
select SUBSTRING_INDEX('i love you too','o',1);
#从开始位置截取到第二个o的位置
select SUBSTRING_INDEX('i love you too','o',2);
#从开始位置截取到第四个o的位置
select SUBSTRING_INDEX('i love you too','o',4);
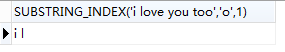
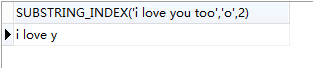

5、字符串索引
LOCATE(substr|column,str|column)
返回substr在str中第一次出现的位置
select LOCATE('good', 'today is a good day');
select LOCATE('le',name) from fruit where id = 1;

LOCATE(substr|column,str|column,pos)
返回substr在str中第pos位置之后第一次出现的位置
select LOCATE('od', 'today is a good day', 1);
select LOCATE('od', 'today is a good day', 10);

POSITION(substr IN str)
select POSITION('love' IN 'i love you');
select POSITION(name IN 'i like apple') from fruit where id = 1;

6、字符串替换
REPLACE(str,from_str,to_str)
select REPLACE('i love you','love','can not forget');
select REPLACE(name,'p','b') from fruit where id = 1;
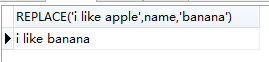
select REPLACE('i like apple',name,'banana') from fruit where id = 1;

7、字符串去空格
select TRIM([remstr FROM] str)
去掉str两端的空格或remstr
select TRIM(' 10610 '), TRIM('10' FROM '10610');

TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
去掉str两端、前端、后端的空格或remstr
select TRIM(BOTH '10' FROM '10610');
select TRIM(LEADING '10' FROM '10610');
select TRIM(TRAILING '10' FROM '10610');

select TRIM(BOTH FROM ' 10610 ');
select TRIM(LEADING FROM ' 10610 ');
select TRIM(TRAILING FROM ' 10610 ');

LTRIM(str)与RTRIM(str)
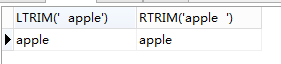
select LTRIM(' apple'), RTRIM('apple ')
8、字符串反转
REVERSE(str)
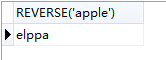
select REVERSE('apple')
四、运用
查询info表中的编码(number)和学生班级(data字段中:Student节点下Class的值):
select number, SUBSTRING(data, LOCATE('<Class>',data) + LENGTH('<Class>'), LOCATE('</Class>',data) - (LOCATE('<Class>',data) + LENGTH('<Class>'))) 'Class' from info
